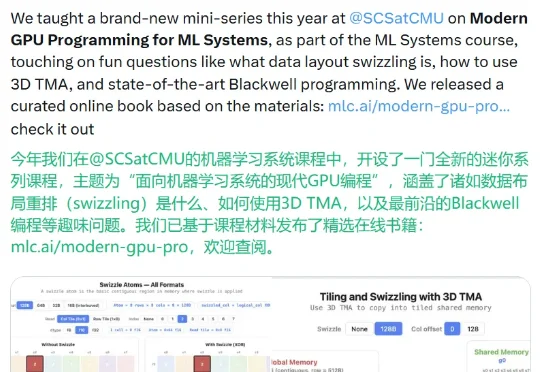
陈天奇新书上线:面向ML系统的现代GPU编程
陈天奇新书上线:面向ML系统的现代GPU编程前些天,CMU 助理教授、TVM/XGBoost/MLC-LLM 的创造者陈天奇发布了一本免费在线书籍《Modern GPU Programming For MLSys(面向机器学习系统的现代 GPU 编程)》。
来自主题: AI资讯
7830 点击 2026-06-27 15:49
 搜索
搜索
前些天,CMU 助理教授、TVM/XGBoost/MLC-LLM 的创造者陈天奇发布了一本免费在线书籍《Modern GPU Programming For MLSys(面向机器学习系统的现代 GPU 编程)》。

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。
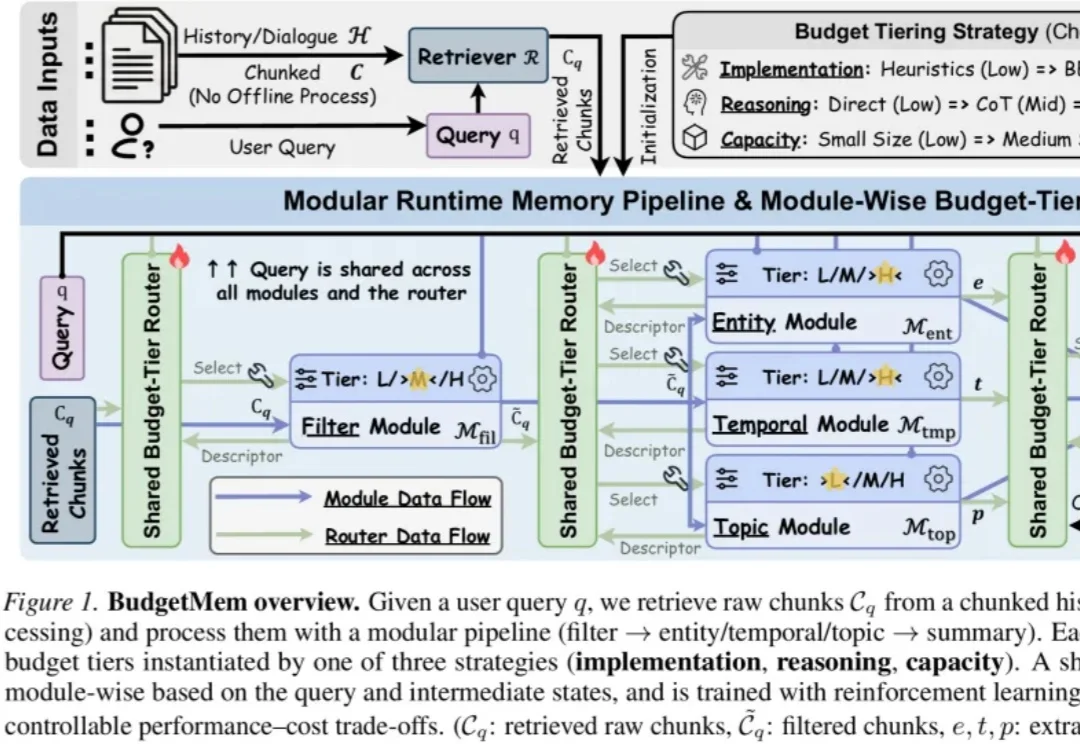
当 LLM Agent 处理长期对话、多轮交互和复杂文档时,Memory 已经成为不可或缺的核心模块。它帮助智能体保存历史、检索信息、维持个性化上下文,并支撑跨时间的推理能力。

近日,Anthropic 发布了一篇引发广泛关注的文章《When AI builds itself》。文中披露了极其惊人的内部数据:截至 2026 年 5 月,Anthropic 超过 80% 的合并代码已由 Claude 编写,工程师的日常代码产出飙升了 8 倍;更令人瞩目的是,AI 智能体已经可以自主提出假设、执行长达数百小时的强化安全实验。

压力之下,刚刚,《连线》记者 Max Zeff 爆料称,Anthropic 正在撤销这一政策。该媒体从 Anthropic 获得了一份声明,其中写到:「我们正在调整 Fable 5 针对前沿 LLM 开发的安全限制,使其变得可见。」
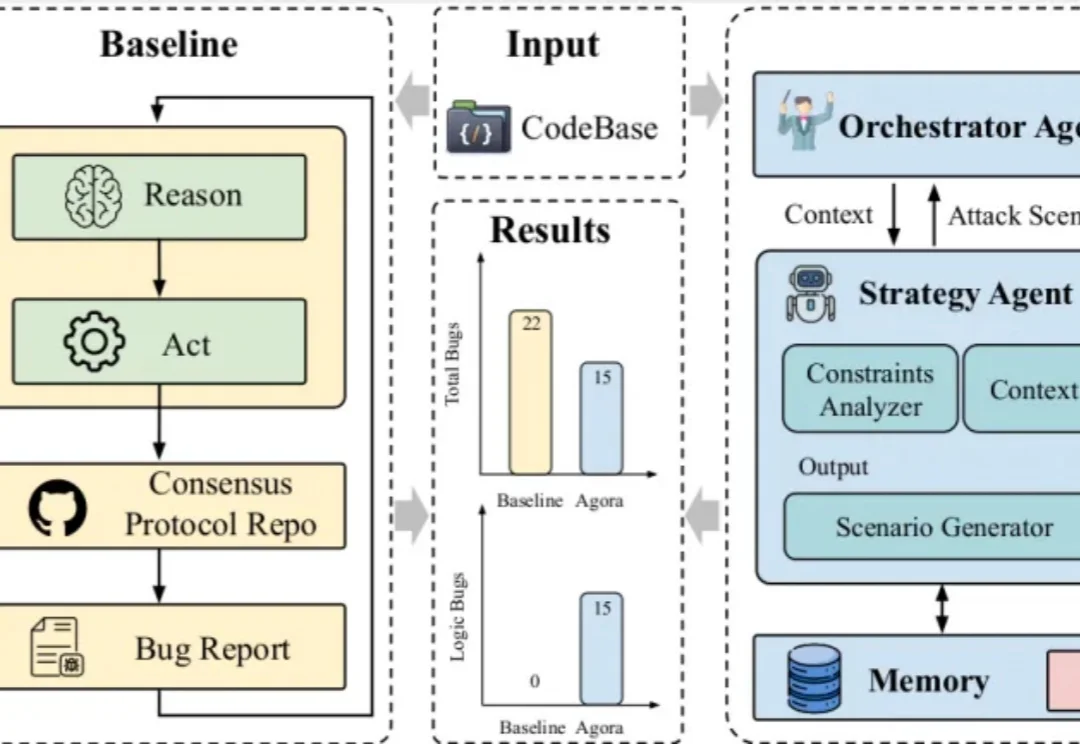
分布式系统的 “圣杯”—— 共识协议(Consensus Protocols),长久以来都是顶级基础设施工程师的 “Bug 地狱”。由于其状态极其复杂、多节点交织,传统测试和单体 LLM 对硬核的 Deep Bug(深层逻辑漏洞)几乎束手无策。
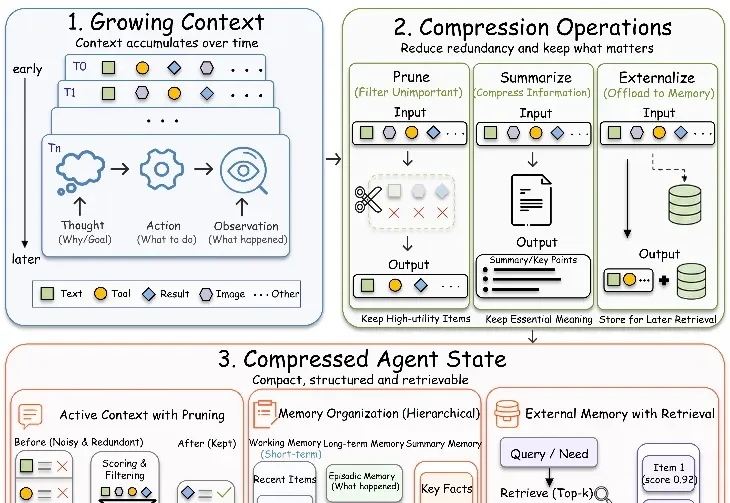
LLM Agent 做长任务时,真正让人头疼的往往不是模型不会推理,而是上下文开始失控:前几步还很清楚,后面就忘约束、丢状态、重复试错,最后把任务跑成事故现场。

还在手动在不同工具间来回切换查文献、跑代码、看结果?两个月前发起内侧的科研龙虾SciClaw,经过上万名科研人的「考核」,正式升级为Mira,推出专家小队、科研画布、LLM WIKI 三大核心能力,首次将「Vibe Researching」理念产品化,让研究者像组建实验室团队一样配置 AI,把时间还给真正的科学思考。

从 LLM 的超长文本处理、视频生成模型的以假乱真、Agent 自主规划与执行的日趋成熟,到 VLA、世界模型等开始进入物理世界,AI 正在不断拓宽其能力边界。
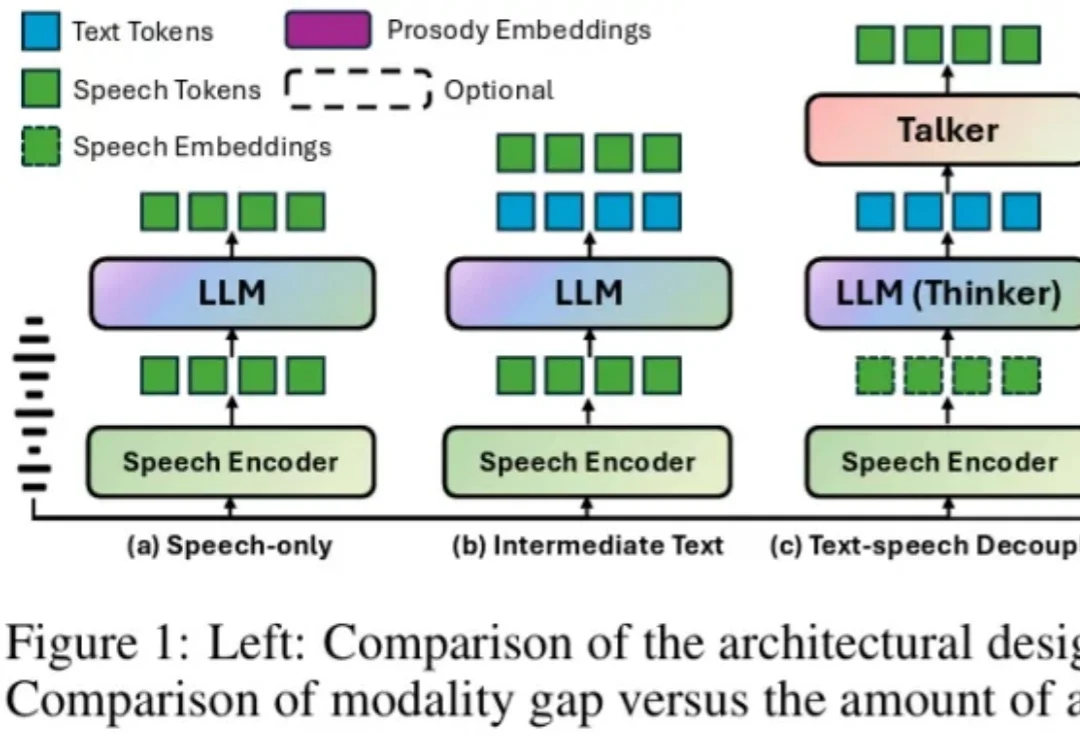
相信大家都有过这样的体验:同一个系列的模型,使用文本交互的时候,模型就像开启了 “最强大脑”,数学代码等各种复杂推理任务样样精通,可是一旦将其改造成语音对话模型之后,性能就猛烈下降,严重 “降智”,经常会犯很多基本的逻辑错误。